Introduction
We present Live Avatar, an algorithm-system co-designed framework that enables real-time,
streaming, and infinite-length interactive avatar video generation.
It is powered by a 14-billion-parameter diffusion model that achieves 20 FPS on 5 H800 GPUs with 4-step sampling.
Critically, it supports Block-wise Autoregressive processing, enabling streaming video generation up to 10,000+ seconds long.
The streaming and real-time nature of Live Avatar unlocks powerful interactions: users can engage in natural, face-to-face conversations via microphone and camera, receiving immediate visual feedback as the avatar responds in real-time.
By integrating Live Avatar with Qwen3-Omni, we enable fully interactive dialogue agents. Below is a demonstration of a streaming, real-time conversation between two autonomous agents:
LiveStream Interaction
Infinite Autoregressive Generation
⚡ Achieving Real-Time Streaming Performance
Real-time streaming interaction requires the model to generate frames faster than playback speed and support unbounded, continuous streaming expansion based on preceding frames. We achieve this by:
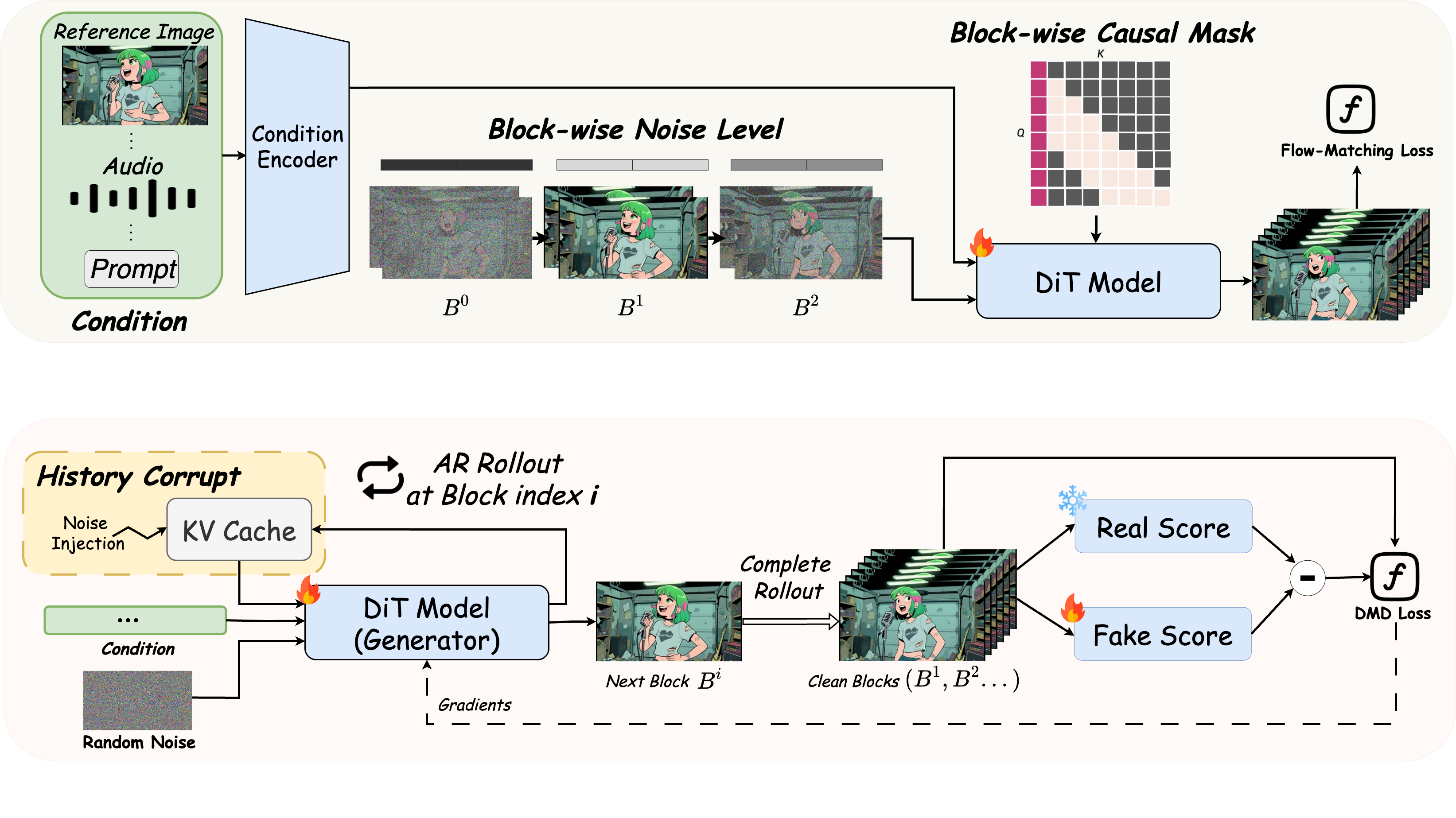
- Employing Distribution Matching Distillation to transform a 14B bidirectional, multi-step video diffusion model into a 4-step streaming one.
- Designing Timestep-forcing Pipeline Parallelism (TPP), a novel paradigm that decouples sequential denoising stages across multiple devices. This method achieves linear speedup proportional to the number of devices, scaling effectively up to the sampling step count.
♾️ Achieving Infinite-length Generation
Existing talking-avatar systems exhibit degradation over long, autoregressive generation—manifesting as identity drift and color shifts. We attribute these long-horizon failures to three internal phenomena:
- inference-mode drift: the conditioning pattern at inference (e.g., the RoPE-relative positioning between the sink frame and current target blocks) gradually diverges from the training-time setup, weakening identity cues.
- distribution drift: the distribution of generated frames progressively deviates from normal, realistic video distributions, likely driven by persistent factors that continuously push the rolling generation toward unrealistic outputs.
- error accumulation: subtle flaws (e.g., slight imperfections) are inherited and compounded frame-by-frame. This difficult-to-recover accumulation causes rapid quality deterioration and incoherent outputs over time.
- Rolling RoPE: Dynamically updating the sink frame’s RoPE to preserve relative positioning, mitigating inference drift to stabilize long-term identity.
- Adaptive Attention Sink (AAS): Replacing the initial reference with a generated frame as the sink to eliminate the persistent factor driving distribution drift.
- History Corrupt: Injecting noise into the KV-cache to simulate inference errors, guiding the model to extract motion from history and stable details from the sink frame.